Artificial neural networks#
Learning objectives#
Know the possibilities, architecture and key components of an artificial neural network.
Understand how neural networks are trained.
Learn how to build neural networks with PyTorch.
Environment setup#
# pylint: disable=wrong-import-position
import os
# Installing the ainotes package is only necessary in standalone runtime environments like Colab
if os.getenv("COLAB_RELEASE_TAG"):
print("Standalone runtime environment detected, installing ainotes package")
%pip install ainotes
# pylint: enable=wrong-import-position
import platform
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
import seaborn as sns
import sklearn
from sklearn.datasets import make_circles
import torch
from torch import nn, optim
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
from ainotes.utils.plot import plot_loss_acc, plot_fashion_images
from ainotes.utils.train import get_device, count_parameters, fit
# Setup plots
# Include matplotlib graphs into the notebook, next to the code
# https://stackoverflow.com/a/43028034/2380880
%matplotlib inline
# Improve plot quality
%config InlineBackend.figure_format = "retina"
# Setup seaborn default theme
# http://seaborn.pydata.org/generated/seaborn.set_theme.html#seaborn.set_theme
sns.set_theme()
# Utility functions
def plot_activation_function(f, f_prime, name, axis=(-6, 6, -1.1, 1.1)):
"""Plot an activation function and its derivative"""
x_min, x_max = axis[0], axis[1]
z = np.linspace(x_min, x_max, 200)
plt.plot(z, f(z), "b-", linewidth=2, label=name)
plt.plot(z, f_prime(z), "g--", linewidth=2, label=f"{name}'")
plt.xlabel("x")
plt.ylabel(f"{name}(x)")
plt.axis(axis)
plt.legend(loc="upper left")
plt.show()
def plot_dataset(x, y):
"""Plot a 2-dimensional dataset with associated classes"""
plt.figure()
plt.plot(x[y == 0, 0], x[y == 0, 1], "or", label=0)
plt.plot(x[y == 1, 0], x[y == 1, 1], "ob", label=1)
plt.legend()
plt.show()
def plot_decision_boundary(model, x, y):
"""Plot the frontier between classes for a 2-dimensional dataset"""
plt.figure()
# Set min and max values and give it some padding
x_min, x_max = x[:, 0].min() - 0.1, x[:, 0].max() + 0.1
y_min, y_max = x[:, 1].min() - 0.1, x[:, 1].max() + 0.1
h = 0.01
# Generate a grid of points with distance h between them
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Compute model output for the whole grid
z = model(torch.from_numpy(np.c_[xx.ravel(), yy.ravel()]).float().to(device))
z = z.reshape(xx.shape)
# Convert PyTorch tensor to NumPy
zz = z.cpu().detach().numpy()
# Plot the contour and training examples
plt.contourf(xx, yy, zz, cmap=plt.colormaps.get_cmap("Spectral"))
cm_bright = ListedColormap(["#FF0000", "#0000FF"])
plt.scatter(x[:, 0], x[:, 1], c=y, cmap=cm_bright)
plt.show()
# Print environment info
print(f"Python version: {platform.python_version()}")
print(f"NumPy version: {np.__version__}")
print(f"scikit-learn version: {sklearn.__version__}")
print(f"PyTorch version: {torch.__version__}")
# PyTorch device configuration
# Performance issues exist with MPS backend for MLP-like models
device, message = get_device(use_mps=False)
print(message)
Python version: 3.11.1
NumPy version: 1.26.4
scikit-learn version: 1.4.1.post1
PyTorch version: 2.2.1
No GPU found, using CPU instead :\
Fundamentals#
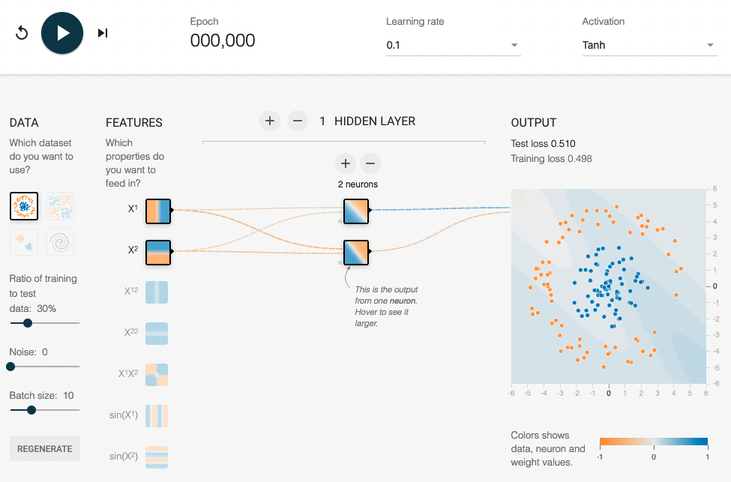
Online playground#
History#
A biological inspiration#
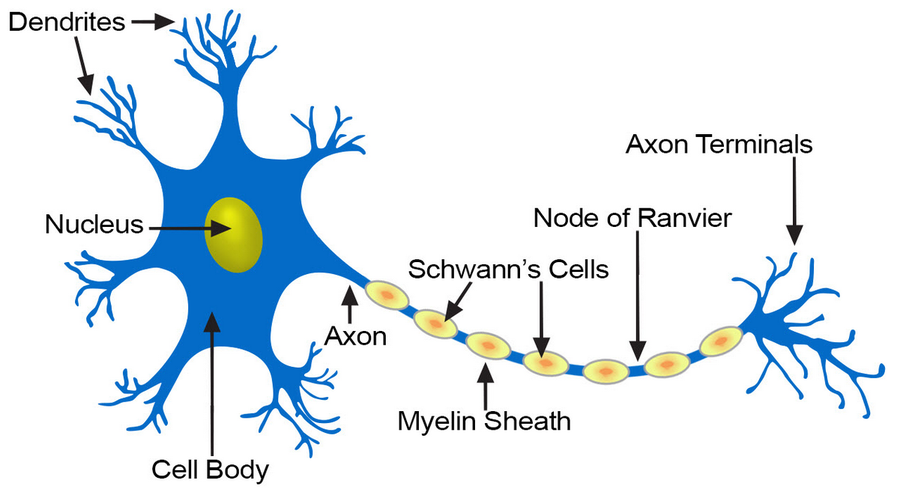
McCulloch & Pitts’ formal neuron (1943)#
Hebb’s rule (1949)#
Attempt to explain synaptic plasticity, the adaptation of brain neurons during the learning process.
“The general idea is an old one, that any two cells or systems of cells that are repeatedly active at the same time will tend to become ‘associated’ so that activity in one facilitates activity in the other.”
Franck Rosenblatt’s perceptron (1958)#
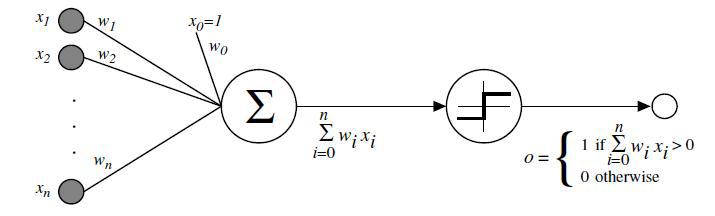
The perceptron learning algorithm#
Init randomly the connection weights \(\pmb{\omega}\).
For each training sample \(\pmb{x}^{(i)}\):
Compute the perceptron output \(y'^{(i)}\)
Adjust weights : \(\pmb{\omega_{t+1}} = \pmb{\omega_t} + \eta (y^{(i)} - y'^{(i)}) \pmb{x}^{(i)}\)
Minsky’s critic (1969)#
One perceptron cannot learn non-linearly separable functions.
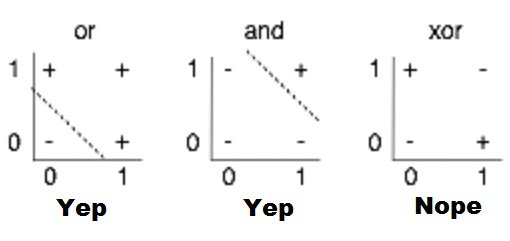
At the time, no learning algorithm existed for training the hidden layers of a MLP.
Decisive breakthroughs (1970s-1990s)#
1974: backpropagation theory (P. Werbos).
1986: learning through backpropagation (Rumelhart, Hinton, Williams).
1989: first researchs on deep neural nets (LeCun, Bengio).
1991: Universal approximation theorem. Given appropriate complexity and appropriate learning, a network can theorically approximate any continuous function.
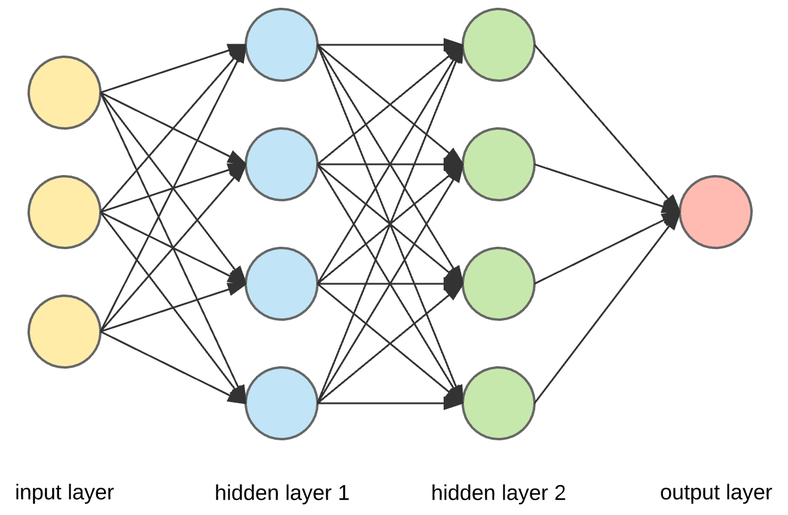
Key components#
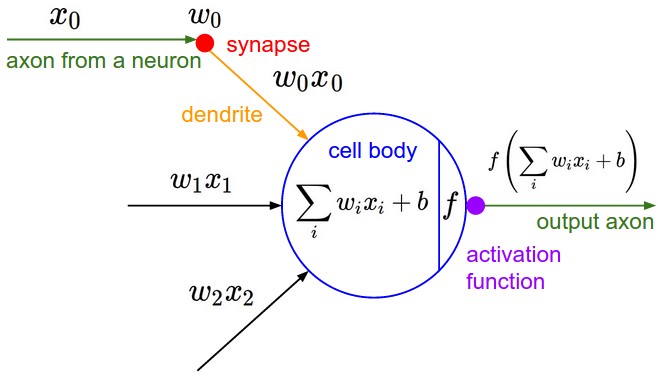
Anatomy of a fully connected network#
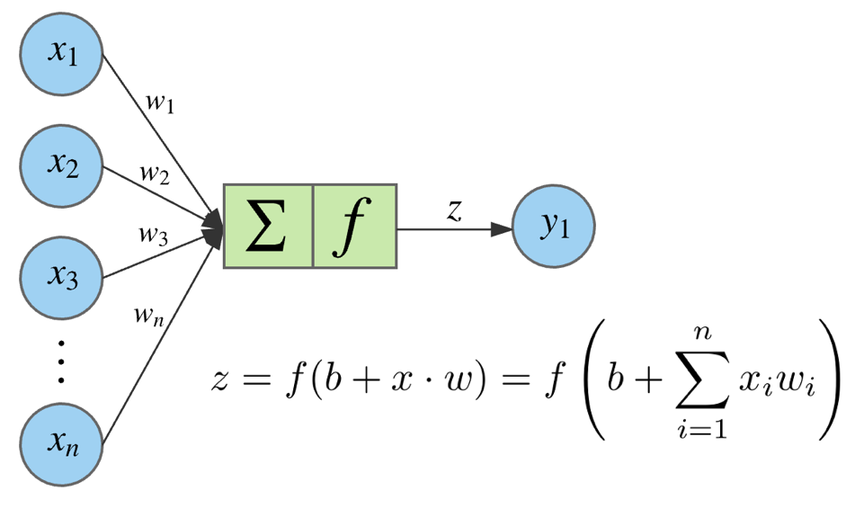
Neuron output#
Activation functions#
They are applied to the weighted sum of neuron inputs to produce its output.
They must be:
non-linear, so that the network has access to a richer representation space and not only linear transformations;
differentiable, so that gradients can be computed during learning.
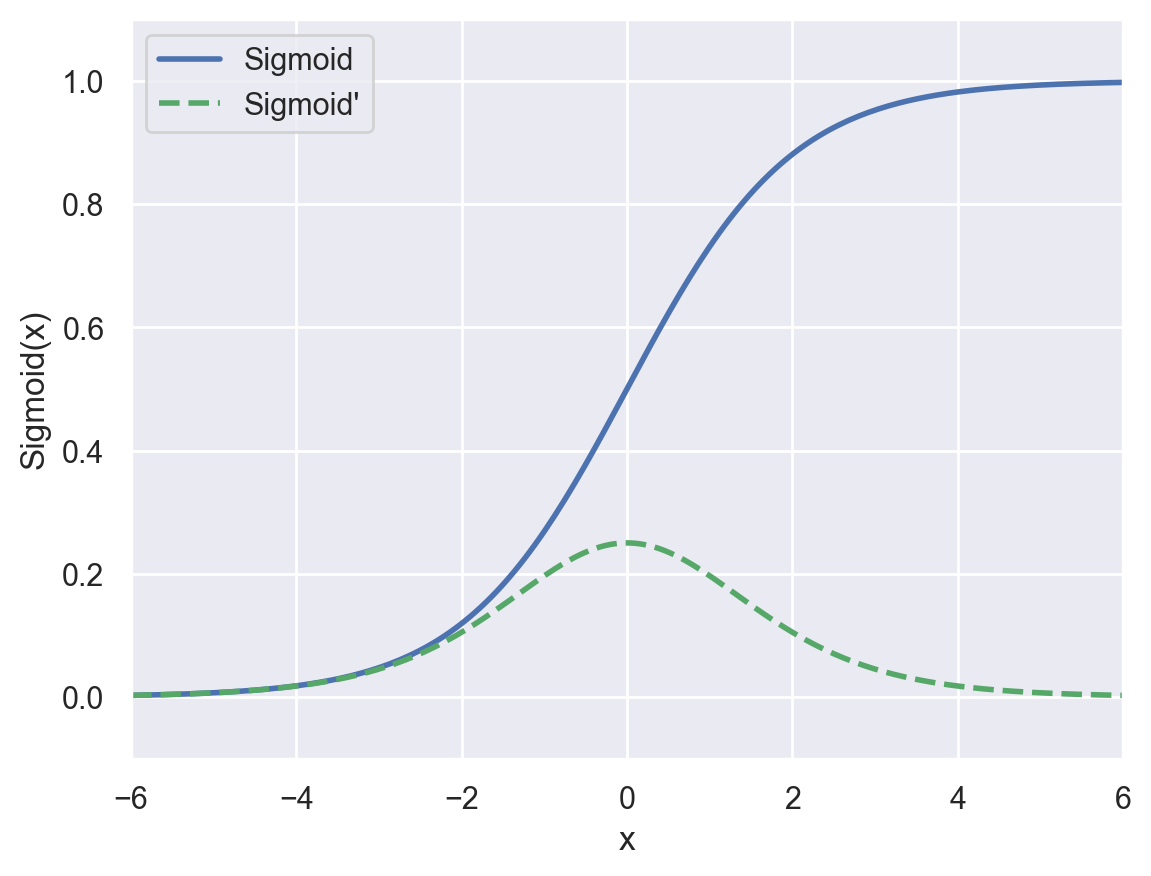
Sigmoid#
This function “squashes” its input between between 0 and 1, outputting something that can be interpreted as the probability of the positive class. It is often used in the final layer of the network for binary classification tasks.
def sigmoid(x):
"""Sigmoid function"""
return 1 / (1 + np.exp(-x))
def sigmoid_prime(x):
"""Derivative of the sigmoid function"""
return sigmoid(x) * (1 - sigmoid(x))
plot_activation_function(sigmoid, sigmoid_prime, "Sigmoid", axis=(-6, 6, -0.1, 1.1))
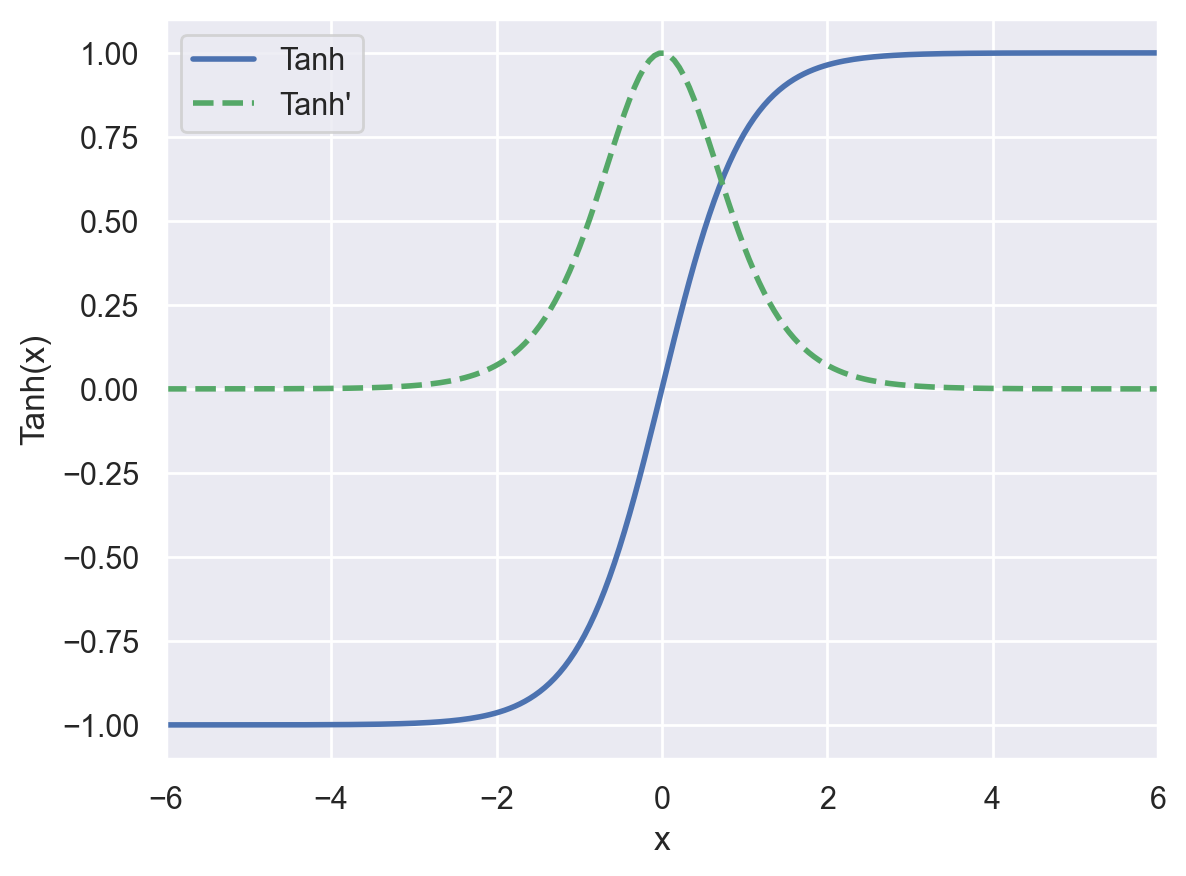
tanh#
The hyperbolic tangent function has a similar shape as sigmoid, but outputs values in the \([-1,1]\) interval.
def tanh(x):
"""Hyperbolic tangent function"""
return 2 * sigmoid(2 * x) - 1
def tanh_prime(x):
"""Derivative of hyperbolic tangent function"""
return 4 / np.square(np.exp(x) + np.exp(-x))
plot_activation_function(tanh, tanh_prime, "Tanh", axis=(-6, 6, -1.1, 1.1))
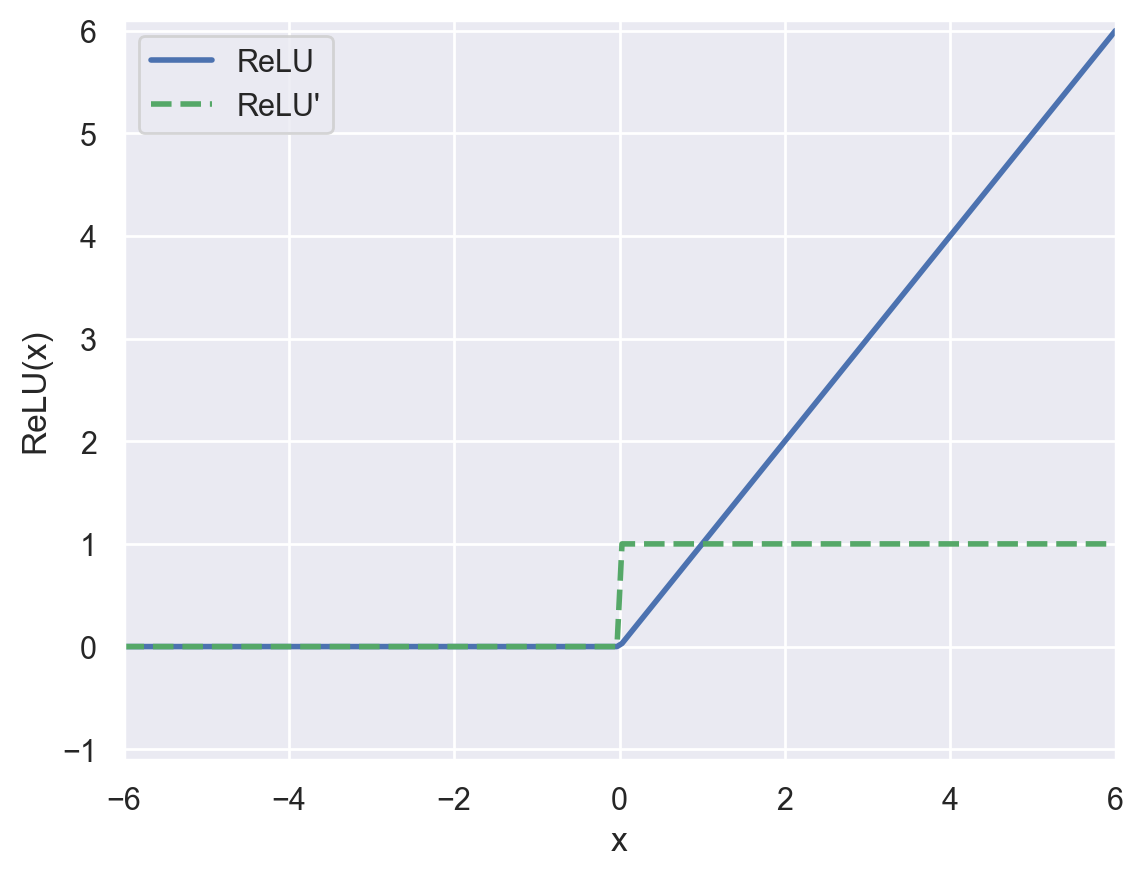
ReLU#
The Rectified Linear Unit function has replaced sigmoid and tanh as the default activation function in most contexts.
def relu(x):
"""Rectified Linear Unit function"""
return np.maximum(0, x)
def relu_prime(x):
"""Derivative of the Rectified Linear Unit function"""
# https://stackoverflow.com/a/45022037
return (x > 0).astype(x.dtype)
plot_activation_function(relu, relu_prime, "ReLU", axis=(-6, 6, -1.1, 6.1))
Training process#
Learning algorithm#
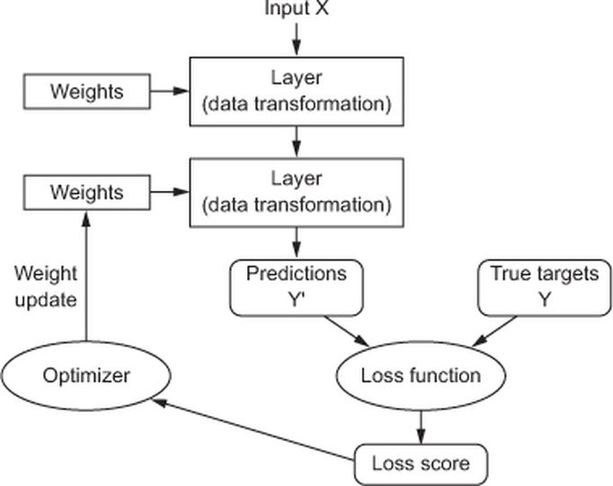
Weights initialization#
To facilitate training, initial weights must be:
non-zero
random
have small values
Several techniques exist. A commonly used one is Xavier initialization.
Weights update#
Objective: minimize the loss function. Method: gradient descent.
Backpropagation#
Objective: compute \(\nabla_{\pmb{\omega}}\mathcal{L}(\pmb{\omega_t})\), the loss function gradient w.r.t. all the network weights.
Method: apply the chain rule to compute partial derivatives backwards, starting from the current output.
Visual demo of backpropagation#
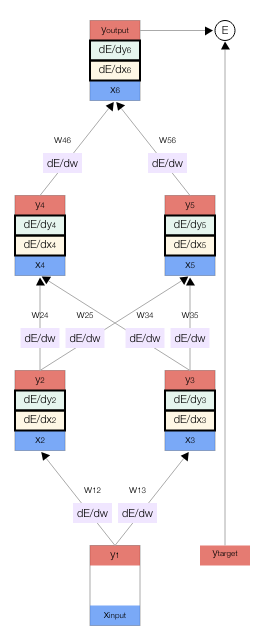
BInary classification example#
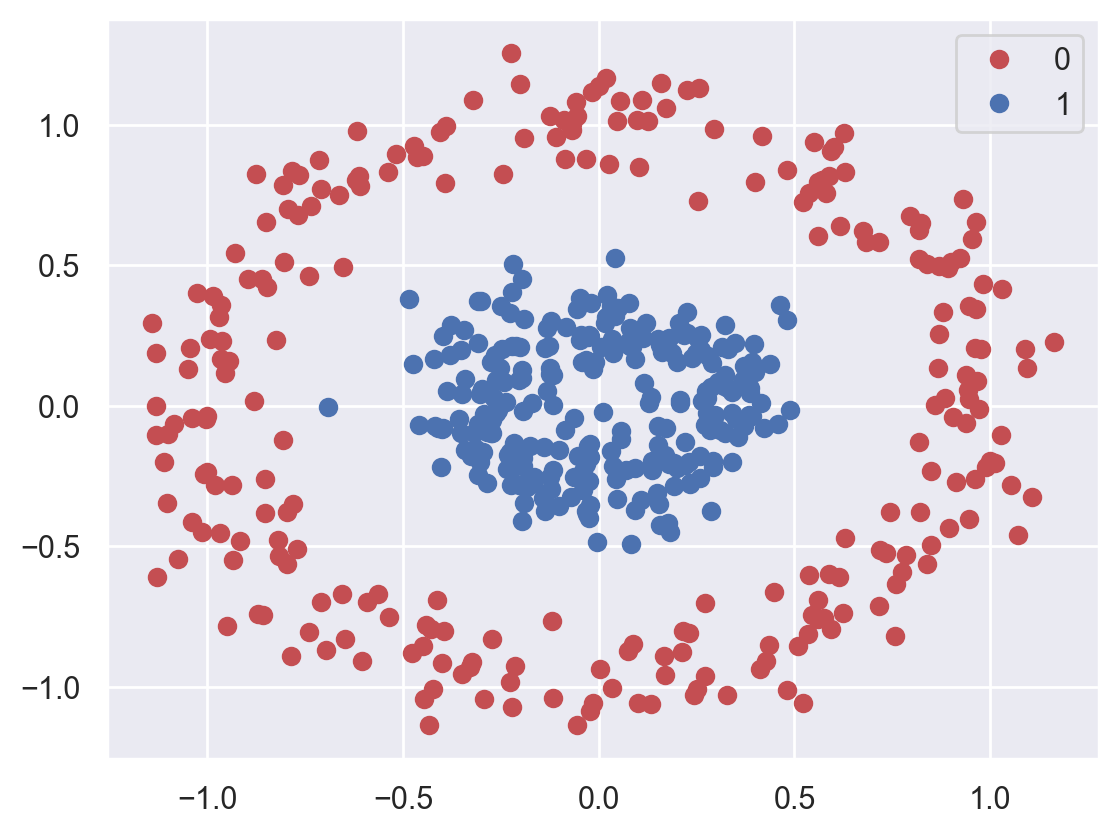
Data generation and visualization#
A scikit-learn function is used to easily generate two-dimensional data with two classes.
# Generate 2D data (a large circle containing a smaller circle)
planar_data, planar_targets = make_circles(n_samples=500, noise=0.1, factor=0.3)
print(f"Data: {planar_data.shape}. targets: {planar_targets.shape}")
print(planar_data[:10])
print(planar_targets[:10])
Data: (500, 2). targets: (500,)
[[-0.45943416 -0.07028865]
[-0.29296977 -1.04292214]
[-0.22404062 -0.28340591]
[ 0.01875137 0.31738188]
[-0.32728777 -0.17831421]
[ 0.18311509 -0.45056598]
[ 0.34037651 -0.02481973]
[ 0.27745991 -0.02731317]
[ 0.25676701 1.12955978]
[-0.05200732 -0.1772228 ]]
[1 0 1 1 1 1 1 1 0 1]
plot_dataset(planar_data, planar_targets)
Hyperparameters#
Hyperparameters (\(\neq\) model parameters) are adjustable configuration values that let you control the model training process.
# Rate of parameter change during gradient descent
learning_rate = 0.1
# An epoch is finished when all data samples have been presented to the model during training
n_epochs = 50
# Number of samples used for one gradient descent step during training
batch_size = 5
# Number of neurons on the hidden layer of the MLP
hidden_layer_size = 2
Data preparation#
Generated data (NumPy tensors) needs to be converted to PyTorch tensors before training a PyTorch-based model. These new tensors are stored in the memory of the available device (GPU ou CPU).
# Create PyTorch tensors from NumPy tensors
x_train = torch.from_numpy(planar_data).float().to(device)
# PyTorch loss function expects float results of shape (batch_size, 1) instead of (batch_size,)
# So we add a new axis and convert them to floats
y_train = torch.from_numpy(planar_targets[:, np.newaxis]).float().to(device)
print(f"x_train: {x_train.shape}. y_train: {y_train.shape}")
x_train: torch.Size([500, 2]). y_train: torch.Size([500, 1])
In order to use mini-batch SGD, data needs to be passed to the model as small, randomized batches during training. The Pytorch DataLoader class abstracts this complexity for us.
# Load data as randomized batches for training
planar_dataloader = DataLoader(
list(zip(x_train, y_train)), batch_size=batch_size, shuffle=True
)
Model definition#
A PyTorch model is defined by combining elementary blocks, known as modules.
Our neural network uses the following ones:
Sequential: an ordered container of modules.
Linear: a linear transformation of its entries, a.k.a. dense or fully connected layer.
# Create a MultiLayer Perceptron with 2 inputs and 1 output
# You may change its internal architecture:
# for example, try adding one neuron on the hidden layer and check training results
planar_model = nn.Sequential(
# Hidden layer with 2 inputs
nn.Linear(in_features=2, out_features=hidden_layer_size),
nn.Tanh(),
# Output layer
nn.Linear(in_features=hidden_layer_size, out_features=1),
nn.Sigmoid(),
).to(device)
print(planar_model)
# Count the total number of trainable model parameters (weights)
print(f"Number of trainable parameters: {count_parameters(planar_model)}")
Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Tanh()
(2): Linear(in_features=2, out_features=1, bias=True)
(3): Sigmoid()
)
Number of trainable parameters: 9
Loss function#
For binary classification tasks, the standard choice is the binary cross entropy loss, conveniently provided by a PyTorch class.
For each sample of the batch, it will compare the output of the model (a value \(\in [0,1]\) provided by the sigmoid function) with the expected binary value \(\in \{0,1\}\).
# Binary cross entropy loss function
planar_loss_fn = nn.BCELoss()
Model training#
The training algorithm is as follows:
On each iteration on the whole dataset (known as an epoch) and for each data batch inside an epoch, the model output is computed on the current batch.
This output is used alongside expected results by the loss function to obtain the mean loss for the current batch.
The gradient of the loss w.r.t. each model parameter is computed (backpropagation).
The model parameters are updated in the opposite direction of their gradient (one GD step).
def fit_planar(dataloader, model, loss_fn, epochs):
"""Main training code"""
for _ in range(epochs):
# Training algorithm for one data batch (i.e. one gradient descent step)
for x_batch, y_batch in dataloader:
# Forward pass: compute model output with current weights
output = model(x_batch)
# Compute loss (comparison between expected and actual results)
loss = loss_fn(output, y_batch)
# Reset the gradients to zero before running the backward pass
# Avoids accumulating gradients between gradient descent steps
model.zero_grad()
# Backward pass (backprop): compute gradient of the loss w.r.t each model weight
loss.backward()
# Gradient descent step: update the weights in the opposite direction of their gradient
# no_grad() avoids tracking operations history, which would be useless here
with torch.no_grad():
for param in model.parameters():
param -= learning_rate * param.grad
# Fit model to planar data
fit_planar(
dataloader=planar_dataloader,
model=planar_model,
loss_fn=planar_loss_fn,
epochs=n_epochs,
)
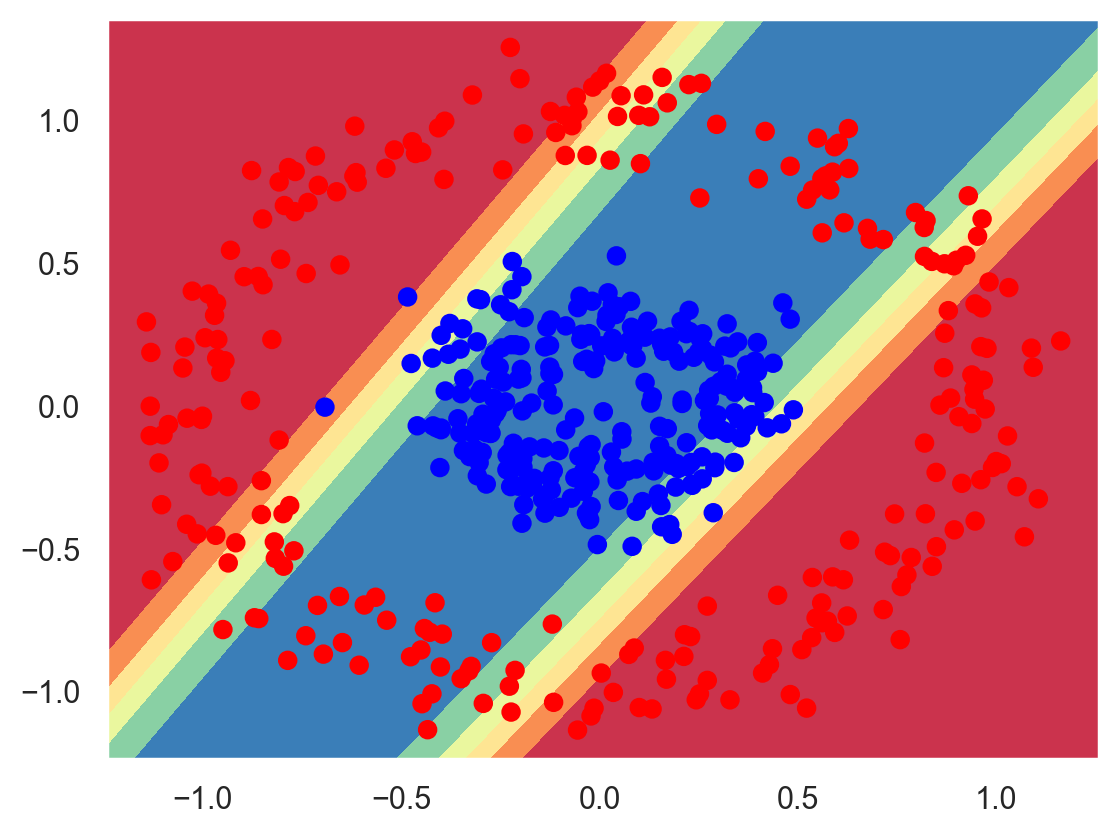
Training results#
plot_decision_boundary(planar_model, planar_data, planar_targets)
Multiclass classification example#
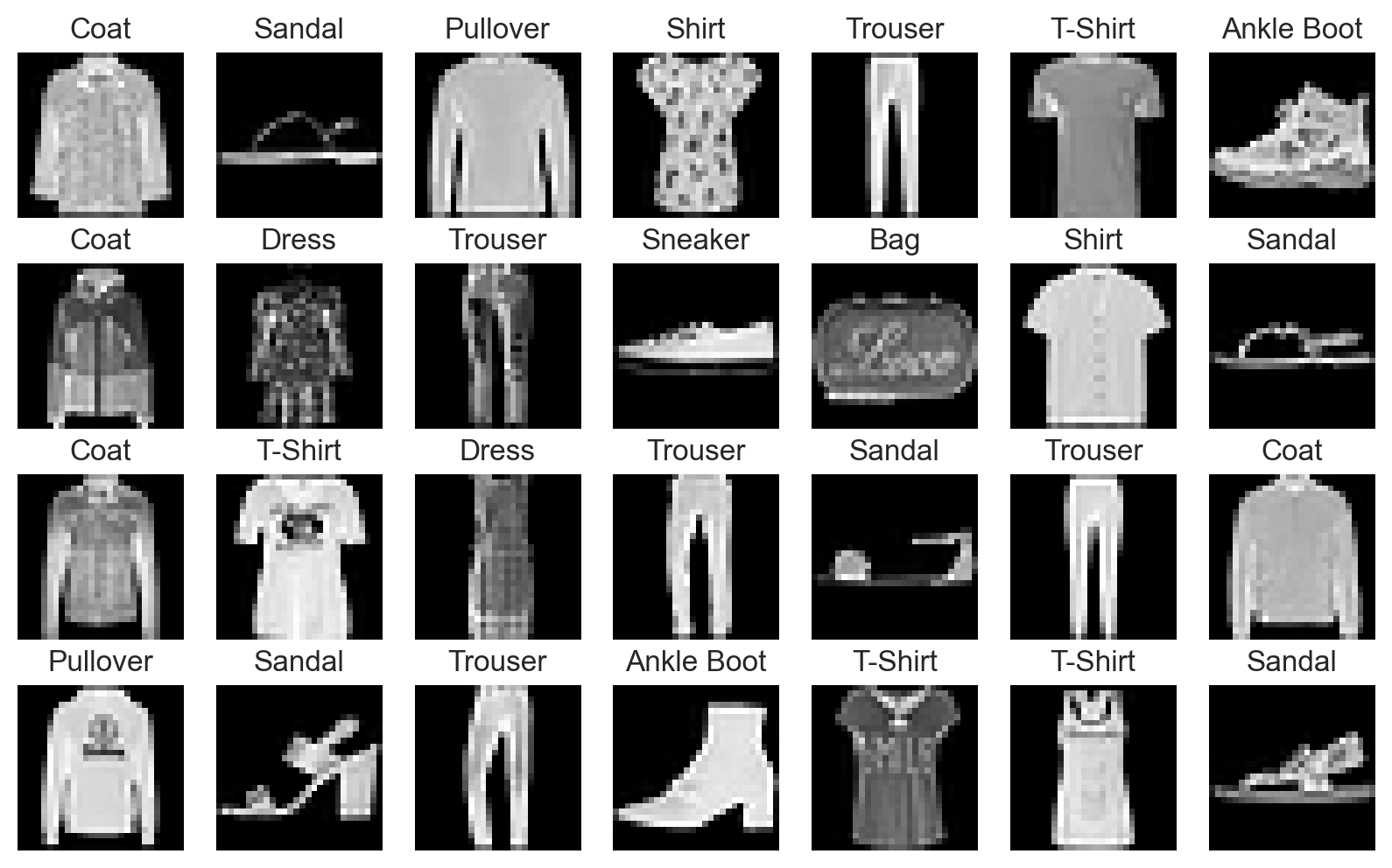
Data loading and visualization#
We use the Fashion-MNIST dataset, analogous to the famous MNIST handwritten digits dataset. It consists of:
a training set containing 60,000 28x28 grayscale images, each of them associated with a label (fashion category) from 10 classes;
a test set of 10,000 images with the same properties.
A PyTorch class simplifies the loading process of this dataset.
fashion_train_data = datasets.FashionMNIST(
root="data", train=True, download=True, transform=ToTensor()
)
fashion_test_data = datasets.FashionMNIST(
root="data", train=False, download=True, transform=ToTensor()
)
# Show info about the first training image
fashion_img, fashion_label = fashion_train_data[0]
print(f"First image: {fashion_img.shape}. Label: {fashion_label}")
First image: torch.Size([1, 28, 28]). Label: 9
# Show raw data for the first image
# Pixel values have already been normalized into the [0,1] range
print(fashion_img)
tensor([[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0039, 0.0000, 0.0000, 0.0510,
0.2863, 0.0000, 0.0000, 0.0039, 0.0157, 0.0000, 0.0000, 0.0000,
0.0000, 0.0039, 0.0039, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0118, 0.0000, 0.1412, 0.5333,
0.4980, 0.2431, 0.2118, 0.0000, 0.0000, 0.0000, 0.0039, 0.0118,
0.0157, 0.0000, 0.0000, 0.0118],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0235, 0.0000, 0.4000, 0.8000,
0.6902, 0.5255, 0.5647, 0.4824, 0.0902, 0.0000, 0.0000, 0.0000,
0.0000, 0.0471, 0.0392, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.6078, 0.9255,
0.8118, 0.6980, 0.4196, 0.6118, 0.6314, 0.4275, 0.2510, 0.0902,
0.3020, 0.5098, 0.2824, 0.0588],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0039, 0.0000, 0.2706, 0.8118, 0.8745,
0.8549, 0.8471, 0.8471, 0.6392, 0.4980, 0.4745, 0.4784, 0.5725,
0.5529, 0.3451, 0.6745, 0.2588],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0039, 0.0039, 0.0039, 0.0000, 0.7843, 0.9098, 0.9098,
0.9137, 0.8980, 0.8745, 0.8745, 0.8431, 0.8353, 0.6431, 0.4980,
0.4824, 0.7686, 0.8980, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.7176, 0.8824, 0.8471,
0.8745, 0.8941, 0.9216, 0.8902, 0.8784, 0.8706, 0.8784, 0.8667,
0.8745, 0.9608, 0.6784, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.7569, 0.8941, 0.8549,
0.8353, 0.7765, 0.7059, 0.8314, 0.8235, 0.8275, 0.8353, 0.8745,
0.8627, 0.9529, 0.7922, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0039, 0.0118, 0.0000, 0.0471, 0.8588, 0.8627, 0.8314,
0.8549, 0.7529, 0.6627, 0.8902, 0.8157, 0.8549, 0.8784, 0.8314,
0.8863, 0.7725, 0.8196, 0.2039],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0235, 0.0000, 0.3882, 0.9569, 0.8706, 0.8627,
0.8549, 0.7961, 0.7765, 0.8667, 0.8431, 0.8353, 0.8706, 0.8627,
0.9608, 0.4667, 0.6549, 0.2196],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0157, 0.0000, 0.0000, 0.2157, 0.9255, 0.8941, 0.9020,
0.8941, 0.9412, 0.9098, 0.8353, 0.8549, 0.8745, 0.9176, 0.8510,
0.8510, 0.8196, 0.3608, 0.0000],
[0.0000, 0.0000, 0.0039, 0.0157, 0.0235, 0.0275, 0.0078, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.9294, 0.8863, 0.8510, 0.8745,
0.8706, 0.8588, 0.8706, 0.8667, 0.8471, 0.8745, 0.8980, 0.8431,
0.8549, 1.0000, 0.3020, 0.0000],
[0.0000, 0.0118, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.2431, 0.5686, 0.8000, 0.8941, 0.8118, 0.8353, 0.8667,
0.8549, 0.8157, 0.8275, 0.8549, 0.8784, 0.8745, 0.8588, 0.8431,
0.8784, 0.9569, 0.6235, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0706, 0.1725, 0.3216, 0.4196,
0.7412, 0.8941, 0.8627, 0.8706, 0.8510, 0.8863, 0.7843, 0.8039,
0.8275, 0.9020, 0.8784, 0.9176, 0.6902, 0.7373, 0.9804, 0.9725,
0.9137, 0.9333, 0.8431, 0.0000],
[0.0000, 0.2235, 0.7333, 0.8157, 0.8784, 0.8667, 0.8784, 0.8157,
0.8000, 0.8392, 0.8157, 0.8196, 0.7843, 0.6235, 0.9608, 0.7569,
0.8078, 0.8745, 1.0000, 1.0000, 0.8667, 0.9176, 0.8667, 0.8275,
0.8627, 0.9098, 0.9647, 0.0000],
[0.0118, 0.7922, 0.8941, 0.8784, 0.8667, 0.8275, 0.8275, 0.8392,
0.8039, 0.8039, 0.8039, 0.8627, 0.9412, 0.3137, 0.5882, 1.0000,
0.8980, 0.8667, 0.7373, 0.6039, 0.7490, 0.8235, 0.8000, 0.8196,
0.8706, 0.8941, 0.8824, 0.0000],
[0.3843, 0.9137, 0.7765, 0.8235, 0.8706, 0.8980, 0.8980, 0.9176,
0.9765, 0.8627, 0.7608, 0.8431, 0.8510, 0.9451, 0.2549, 0.2863,
0.4157, 0.4588, 0.6588, 0.8588, 0.8667, 0.8431, 0.8510, 0.8745,
0.8745, 0.8784, 0.8980, 0.1137],
[0.2941, 0.8000, 0.8314, 0.8000, 0.7569, 0.8039, 0.8275, 0.8824,
0.8471, 0.7255, 0.7725, 0.8078, 0.7765, 0.8353, 0.9412, 0.7647,
0.8902, 0.9608, 0.9373, 0.8745, 0.8549, 0.8314, 0.8196, 0.8706,
0.8627, 0.8667, 0.9020, 0.2627],
[0.1882, 0.7961, 0.7176, 0.7608, 0.8353, 0.7725, 0.7255, 0.7451,
0.7608, 0.7529, 0.7922, 0.8392, 0.8588, 0.8667, 0.8627, 0.9255,
0.8824, 0.8471, 0.7804, 0.8078, 0.7294, 0.7098, 0.6941, 0.6745,
0.7098, 0.8039, 0.8078, 0.4510],
[0.0000, 0.4784, 0.8588, 0.7569, 0.7020, 0.6706, 0.7176, 0.7686,
0.8000, 0.8235, 0.8353, 0.8118, 0.8275, 0.8235, 0.7843, 0.7686,
0.7608, 0.7490, 0.7647, 0.7490, 0.7765, 0.7529, 0.6902, 0.6118,
0.6549, 0.6941, 0.8235, 0.3608],
[0.0000, 0.0000, 0.2902, 0.7412, 0.8314, 0.7490, 0.6863, 0.6745,
0.6863, 0.7098, 0.7255, 0.7373, 0.7412, 0.7373, 0.7569, 0.7765,
0.8000, 0.8196, 0.8235, 0.8235, 0.8275, 0.7373, 0.7373, 0.7608,
0.7529, 0.8471, 0.6667, 0.0000],
[0.0078, 0.0000, 0.0000, 0.0000, 0.2588, 0.7843, 0.8706, 0.9294,
0.9373, 0.9490, 0.9647, 0.9529, 0.9569, 0.8667, 0.8627, 0.7569,
0.7490, 0.7020, 0.7137, 0.7137, 0.7098, 0.6902, 0.6510, 0.6588,
0.3882, 0.2275, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.1569,
0.2392, 0.1725, 0.2824, 0.1608, 0.1373, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000]]])
# Labels, i.e. fashion categories associated to images (one category per image)
fashion_labels = (
"T-Shirt",
"Trouser",
"Pullover",
"Dress",
"Coat",
"Sandal",
"Shirt",
"Sneaker",
"Bag",
"Ankle Boot",
)
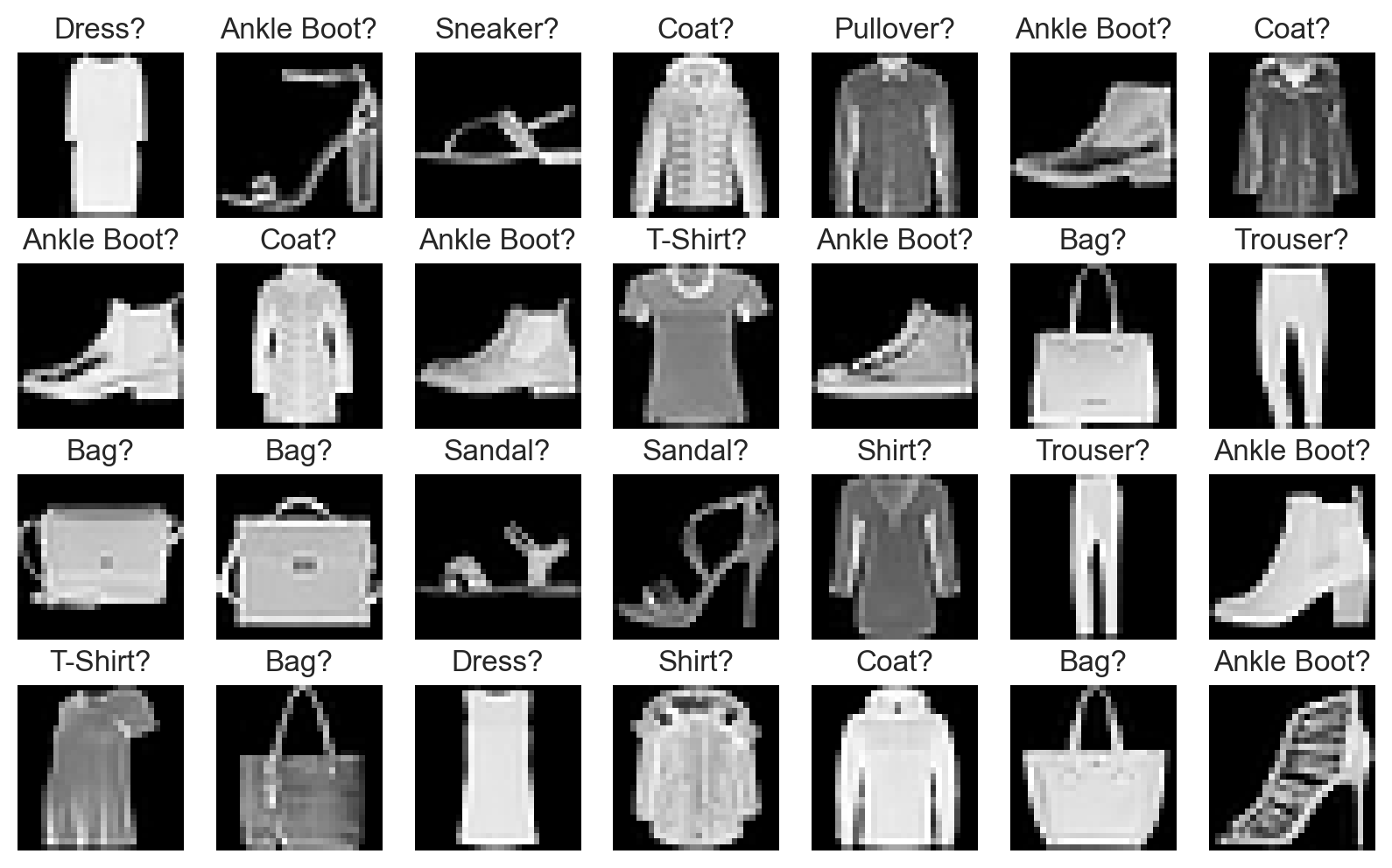
plot_fashion_images(data=fashion_train_data, labels=fashion_labels, device=device)
Hyperparameters#
# Try to change the learning rate to 1e-2 ans check training results
learning_rate = 1e-3
n_epochs = 10
batch_size = 64
Data preparation#
As always, data will be passed to the model as small, randomized batches during training.
fashion_train_dataloader = DataLoader(fashion_train_data, batch_size=batch_size)
fashion_test_dataloader = DataLoader(fashion_test_data, batch_size=batch_size)
Model definition#
Most PyTorch models are defined as subclasses of the Module class. Their constructor creates the layer architecture and their forward method defines the forward pass of the model.
In this model, we use the Flatten module that transforms an input tensor of any shape into a vector (hence its name).
class NeuralNetwork(nn.Module):
"""Neural network for fashion articles classification"""
def __init__(self):
super().__init__()
# Flatten the input image of shape (1, 28, 28) into a vector of shape (28*28,)
self.flatten = nn.Flatten()
# Define a sequential stack of linear layers and activation functions
self.layer_stack = nn.Sequential(
# First hidden layer with 784 inputs
nn.Linear(in_features=28 * 28, out_features=64),
nn.ReLU(),
# Second hidden layer
nn.Linear(in_features=64, out_features=64),
nn.ReLU(),
# Output layer
nn.Linear(in_features=64, out_features=10),
)
def forward(self, x):
"""Define the forward pass of the model"""
# Apply flattening to input
x = self.flatten(x)
# Compute output of layer stack
logits = self.layer_stack(x)
# Logits are a vector of raw (non-normalized) predictions
# This vector contains 10 values, one for each possible class
return logits
fashion_model = NeuralNetwork().to(device)
print(fashion_model)
# Try to guess the total number of parameters for this model before running this code!
print(f"Number of trainable parameters: {count_parameters(fashion_model)}")
NeuralNetwork(
(flatten): Flatten(start_dim=1, end_dim=-1)
(layer_stack): Sequential(
(0): Linear(in_features=784, out_features=64, bias=True)
(1): ReLU()
(2): Linear(in_features=64, out_features=64, bias=True)
(3): ReLU()
(4): Linear(in_features=64, out_features=10, bias=True)
)
)
Number of trainable parameters: 55050
Loss function#
The standard choice for multiclass classification tasks is the cross entropy loss a.k.a. negative log-likelihood loss, provided by a PyTorch class aptly named CrossEntropyLoss.
PyTorch also offers the NLLLoss class implementing the negative log-likelihood loss. A key difference is that
CrossEntropyLossexpects logits (raw, unnormalized predictions) as inputs, and uses LogSoftmax to transform them into probabilities before computing its output. UsingCrossEntropyLossis equivalent to applyingLogSoftmaxfollowed byNLLLoss(more details).
Softmax#
The softmax function turns a vector \(\pmb{v} = \{v_1, v_2, \dots, v_K \} \in \mathbb{R}^K\) of raws values (called a logits vector when it’s the output of a ML model) into a probability distribution. It is a multiclass generalization of the sigmoid function.
\(K\): number of labels.
\(\pmb{v}\): logits vector, i.e. raw predictions for each class.
\(\sigma(\pmb{v})_k \in [0,1]\): probability associated to label \(k \in [1,K]\).
def softmax(x):
"""Softmax function"""
return np.exp(x) / sum(np.exp(x))
# Raw values (logits)
raw_predictions = [3.0, 1.0, 0.2]
probas = softmax(raw_predictions)
print(probas)
# Sum of all probabilities is equal to 1
print(sum(probas))
[0.8360188 0.11314284 0.05083836]
0.9999999999999999
Optimization algorithm#
PyTorch provides out-of-the-box implementations for many gradient descent optimization algorithms (Adam, RMSProp, etc).
We’ll stick with vanilla mini-batch SGD for now.
Model training#
In order to obtain more details about the training process, we define a fit function that encapsulates the training code and computes metrics.
# Fit model to fashion images
fashion_history = fit(
dataloader=fashion_train_dataloader,
model=fashion_model,
loss_fn=nn.CrossEntropyLoss(),
optimizer=optim.SGD(fashion_model.parameters(), lr=learning_rate),
epochs=n_epochs,
device=device,
)
Training started! 60000 samples. 938 batches per epoch
100%|███████████████████████████████████████████████████████| 938/938 [00:02<00:00, 369.79batches/s]
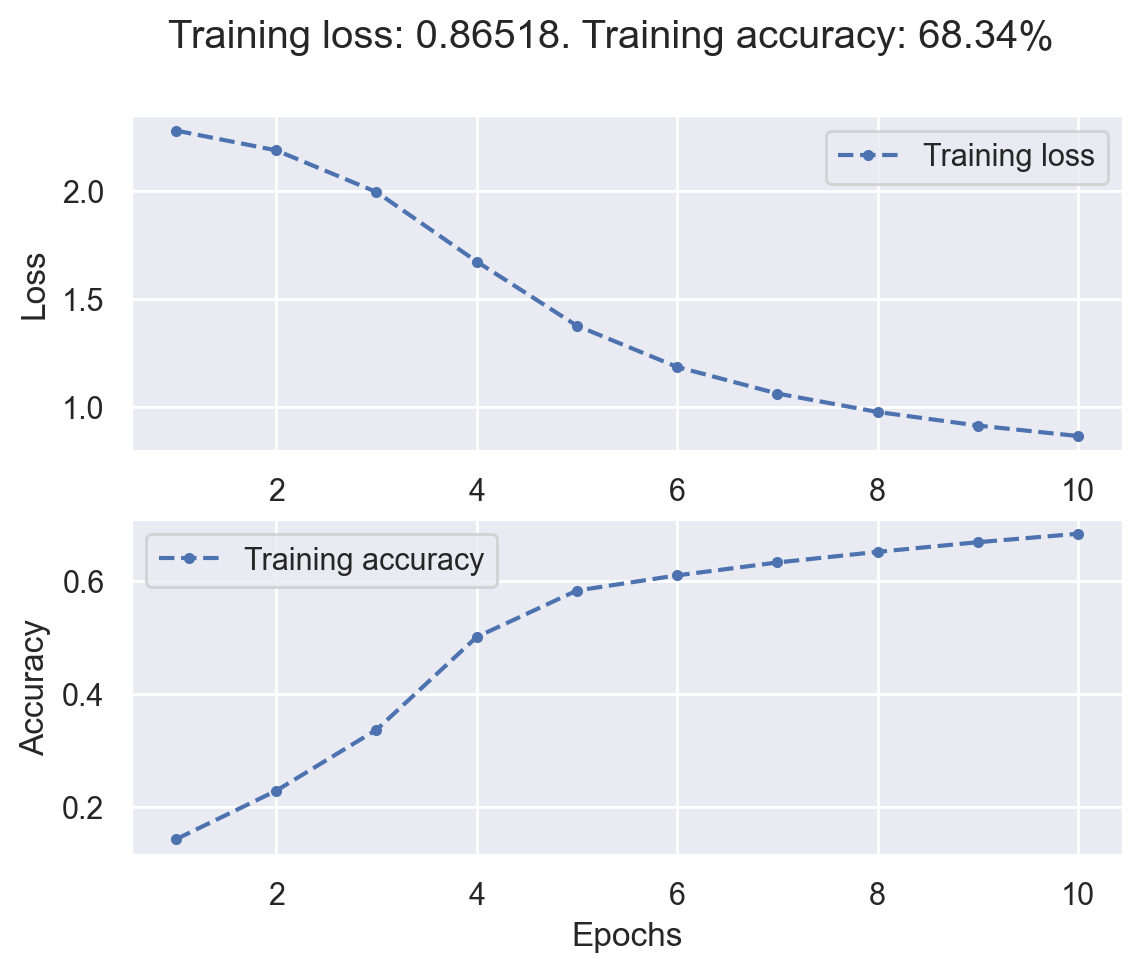
Epoch [ 1/ 10] finished. Mean loss: 2.27774. Accuracy: 14.34%
100%|███████████████████████████████████████████████████████| 938/938 [00:02<00:00, 377.81batches/s]
Epoch [ 2/ 10] finished. Mean loss: 2.18621. Accuracy: 22.92%
100%|███████████████████████████████████████████████████████| 938/938 [00:02<00:00, 333.47batches/s]
Epoch [ 3/ 10] finished. Mean loss: 1.99362. Accuracy: 33.69%
100%|███████████████████████████████████████████████████████| 938/938 [00:03<00:00, 300.13batches/s]
Epoch [ 4/ 10] finished. Mean loss: 1.67215. Accuracy: 50.09%
100%|███████████████████████████████████████████████████████| 938/938 [00:02<00:00, 372.57batches/s]
Epoch [ 5/ 10] finished. Mean loss: 1.37534. Accuracy: 58.30%
100%|███████████████████████████████████████████████████████| 938/938 [00:03<00:00, 307.32batches/s]
Epoch [ 6/ 10] finished. Mean loss: 1.18469. Accuracy: 60.98%
100%|███████████████████████████████████████████████████████| 938/938 [00:02<00:00, 312.74batches/s]
Epoch [ 7/ 10] finished. Mean loss: 1.06171. Accuracy: 63.26%
100%|███████████████████████████████████████████████████████| 938/938 [00:02<00:00, 315.81batches/s]
Epoch [ 8/ 10] finished. Mean loss: 0.97653. Accuracy: 65.14%
100%|███████████████████████████████████████████████████████| 938/938 [00:02<00:00, 325.41batches/s]
Epoch [ 9/ 10] finished. Mean loss: 0.91368. Accuracy: 66.84%
100%|███████████████████████████████████████████████████████| 938/938 [00:02<00:00, 327.44batches/s]
Epoch [ 10/ 10] finished. Mean loss: 0.86518. Accuracy: 68.34%
Training complete! Total gradient descent steps: 9380
Training results#
plot_loss_acc(fashion_history)
plot_fashion_images(
data=fashion_train_data, labels=fashion_labels, device=device, model=fashion_model
)